Last December, Meta AI released paper describing their Byte Latent Transformer (BLT) and today (13 May 2025), they released the weights to Hugging Face.
Let’s break down the paper and explore what makes BLT a special model.
What is BLT?
Let’s break down the name:
• Byte: This signifies that the architecture operates directly on raw byte data • Latent: This refers to the way BLT processes the byte data. Instead of processing every individual byte in the main computation layer (which would be prohibitively costly) • Transformer: This indicates that BLT is an LLM architecture based on the Transformer model
What does this mean in practice. First off, BLT is a tokenizer free architecture. This means it’s not suspectable to errors of tokenising text, fixed set of vocabulary, spelling errors, etc. Instead, BLT learns directly from raw byte level data. It groups bytes into dynamically sized batches – this hopefully helps with more niche fields where subtle differences between words mean a lot.
Dynamic Patching
How does it decide where each block begins and ends? Authors compare a raft of ways to setting the size of each patch, from fixed length, white space, and Byte Pair Encoding (BPE), I’ve attached an image from the original paper highlighting the differences.

In the end, authors settled on Entropy. High entropy means lots of possibilities, less certain predictable is in what follows next. In patches of where there is high entropy, BLT will make shorter batches rather than long batches in low entropy-based areas. This entropy-based approach is what gives it its dynamic batching – compared to white spaced or fixed length batching.
How does it do it?
BLT is composed of a large global autoregressive language model. It’s comprised of three parts:
- Local encoder
- Latent global transformer
- Local decoder
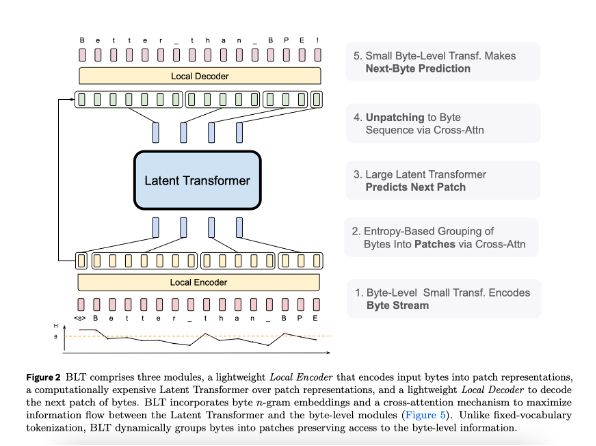
The local encoder is a lightweight transformer model, whose main role is to map a sequence of input bytes to expressive patch representations. It’s noted that a “primary departure from the transformer architecture is the addition of a cross-attention layer after each transformer layer, whose function is to pool byte representations into patch representations”.
Back to the model, embeddings and hash embeddings. Authors use a hash function of n-gram embeddings to help build robust, expressive representations to incorporate information about the preceding bytes. So, the local encoder isn’t just looking at individual bytes, it’s seeing them in the context of its neighbouring bytes to learn the context in which they appear. This helps to build stable and strong patch representations.
Note, that expressive patch representations are learned dense representations outputted by the local encoder here. So, as we would expect if we were to tokenise and embed – we are going from a ‘sparse’ environment to a dense one. Although, BLT omits the need for tokenizing.
The latent global transformer is the heart of the model. It’s the most computationally intensive part of BLT. The latent global transformer takes the output of the local encoder, patch representations and maps them to output patch representations. Let’s look at a few details of the latent global transformer:
- Uses a causal mask. This restricts attention to the current and preceding batch.
- Uses rotary positional embeddings (RoPE). RoPE is an embedding technique that is used to encode positional information (of bytes in this case) into a model’s attention mechanism. RoPE achieves this without fixed or learned positional embeddings.
This overall, isn’t too dissimilar the architecture from Meta’s Llama 3 models which also use RoPE.
The local decoder is like the local encoder, it’s also a lightweight transformer model again using a cross-attention layer to pool. It takes the process patched representations from the global transformer back into bytes.
So, what’s the benefit?
Byte level data can be likened to character level approaches. BLT looks to offer improvements over tokenised approaches for noisy inputs and provide a deeper understanding of sub-word structures. It works well on less common or long-tail vocabularies.
Dynamic patching efficiently allocates compute based on data complexity, potentially leading to inference efficiency improvements. Authors exhibit this by illustrating that up to 50% fewer FLOPS are needed compared to Llama3.
I think the core takeaway, is that BLT is a truly novel way of training LLMs – by skipping tokenizer based approaches. The dynamic batching also helps in more compute efficient. It’s certainly a unique way to think, although can be compared to character level approaches.