I want to open this post by stating that privacy within large language models (LLMs) is a mammoth topic that spans much more than can be said in a single post.
Instead, I want to narrow the focus of the post to showcase some approaches of introducing proprietary data into LLMs, with privacy and safety of sensitive data at the forefront.
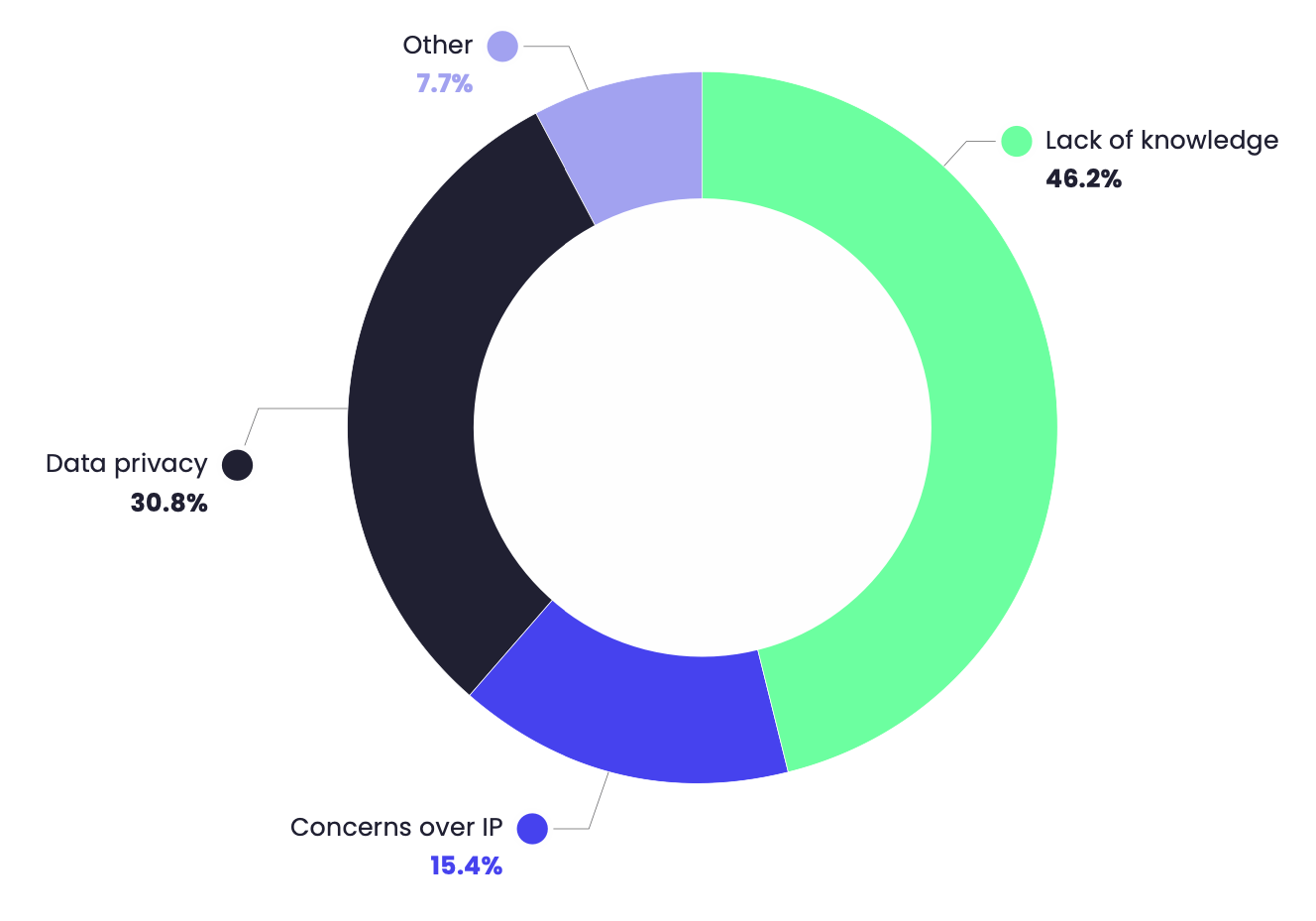
In a study done by the AI Accelerator Institute, data privacy was the second biggest barrier to adopting LLMs within their company
On top of this, governing agencies have been rushing to regulate or set guidelines for generative AI. At the top, the EU has been the most vocal and proactive in regulating AI and data privacy. Examples being the introduction of GDPR. And more recently the agreement of regulation on AI applications with the AI regulation act introduced early Dec 2023.
One of the risks the European Data Protection Supervisor highlight within LLM is the leakage of personal information. There are three main areas where this may happen:
- The model training data may contain personal or sensitive information
- Introduced data may contain personal or sensitive information
- Hallucinations may be real enough to be conceived as personal or sensitive information, where in fact they are hallucinations.
There is a sense that for many privacy conscious companies, that generative AI can’t be used. This post wants to highlight a couple of ways that even privacy conscious companies may be able to introduce private data with generative AI to their stack.
Towards Privacy
Redaction

The legal industry is built upon redactions, and have you ever tried filing a request under the Official information act? You’ll see many parts of text have simply been redacted.
Redaction is an effective, but blunt force tool for ensuring privacy. But its drawbacks are numerous: • It is only effective as the person doing the redactions • Redaction is often a manual time-consuming task • Depending on your application, the text may not be suitable for LLMs creating disjointed confusing sentences.
The uses for redacted data
Redacted data can be used within retrieval augmented generation (RAG), with the redacted data acting as a knowledge base or vector store. The data being redacted, reduces the risk of privacy leakage.
Further, the redacted data could be used for fine-tuning of an existing foundation model.
Why not redact?
For many machine learning applications, it’s the time-consuming nature that makes redaction infeasible. Take for example, fine-tuning an LLM for customer support applications. The cost to redact the customer support queries would quickly get out of control!
Introducing Differential Privacy
Differential privacy is a technique that has gained popularity in recent years. Differential privacy is a technique of ensuring privacy within machine learning applications. At its core, it allows for effective data analysis while maintaining formal privacy guarantees.
Big tech companies such as Apple, Meta, and many others are actively using differential privacy techniques as they strengthen their privacy posture.
Differential privacy has been proposed in many academic papers to be the de-facto for GDPR compliance (PDF link). One of the main promises behind differential privacy is that individual data points aren’t inadvertently memorised and in theory if it were removed – it would have little effect on model performance. This statement alone rings in a similar tone to the right to be forgotten premise within GDPR.
It works, by adding additional noise to a dataset, this added noise is accounted for. The accounting of the noise allows for accurate analysis of the data but maintains privacy for the individual observations.
To be clear, I envision differential privacy only becoming relevant within the fine-tuning of LLMs, not as part of retrieval within a RAG design.
Probably the biggest downside to differential privacy is the introduction of noise. This creates a natural tradeoff between the model utility (accuracy) and privacy. The degree to which you add noise will make your model more private, but at a cost of accuracy.
To date, I haven’t seen many applications of applying differential privacy to LLMs. My next post will hopefully be sharing the results of applying differential privacy to LLMs.